
Meet these two not-so-close siblings: Apache Cass and Lady Munga. Thanks to Amazon Dynamo DB, Cass was born in some ways in 2008 and is older than Lady Munga who was born in 2009. Their primary purpose of existence in the town of database is to remember “stuff”. They both, like many other citizens such as MySQL, Oracle, HBase, PostgresDB, MariaDB, Microsoft SQL, CouchDB are famous and reliable.
No two people are ever the same and such is the case with Apache Cass and Lady Munga. Though they follow their mother, Not-only-SQL paradigm by heart, they are different and beautiful in their own unique being. Cass believes in equality, she among all the citizens vouches for equal rights to all its nodes in the cluster, none is master, none is slave, all are equal when it comes to the answering power. The other lady believes structure in society comes from hierarchy, a master to rule them all, believes in elections and democracy to vote for the leader, god-forbid what will happen when and if the master passes away.
Since they both follow their mother (NoSQL), they both lack consistency. They might provide a stale answer for the question in hand. On the other hand, both support horizontal scalability on commodity hardware. With the omnipresence of big data, the trade-off is desirable for most of the business use cases.
Miss Cass compensates for the lack of consistency by providing support for decentralization, scalability, fault tolerance and multi-data center level replication. Interestingly, the good-hearted Cass also provides a mechanism to keep the system consistent with an innovative and simple concept termed as “Tunable Consistency”. Lady Munga, however, provides support for Ad hoc, simple querying for any field in the document, primary and secondary indexing, server side JavaScript support, aggregation framework file system support, scalability and map-reduce support to compensate for inconsistency.
Lady Munga’s heart is made up of C++ code and is able to performant when it comes to reading the data from the system. On December 16, 2014, to compensate for the slow writes, Munga befriended wiredTigerInc (ehhh Tiger). This friendship brought great value and quality in Munga’s life. Her writing became more efficient and reading performance remained consistent. Cass, on the other hand, at its core is made for writing efficiency from the inception. Below charts portray the performance nature of both.
[Author strongly recommends reading articles provided in references section. Snippets which correspond to high write and low read load are only shared below]
This is what friends of Cass have to say about Cass and Munga.
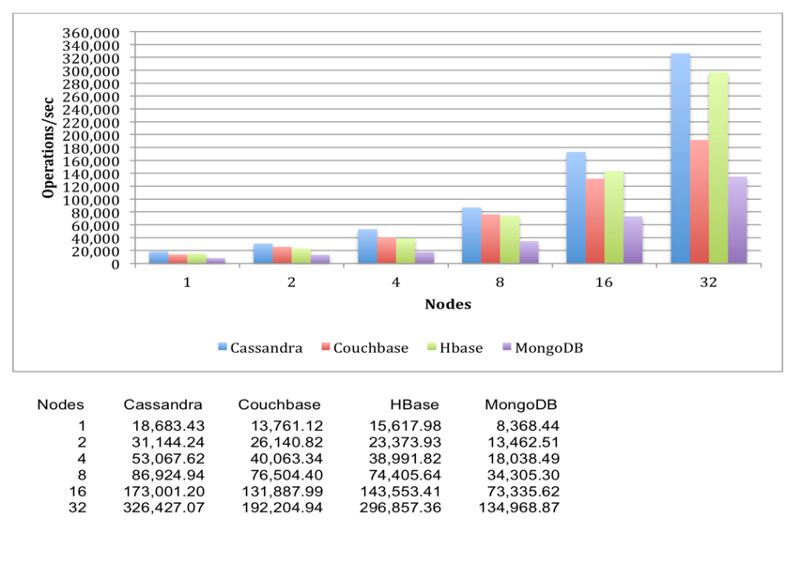
Data Ingestion Performance (Majority Writes)
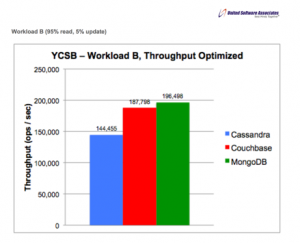
Below charts are results from Munga’s friends:
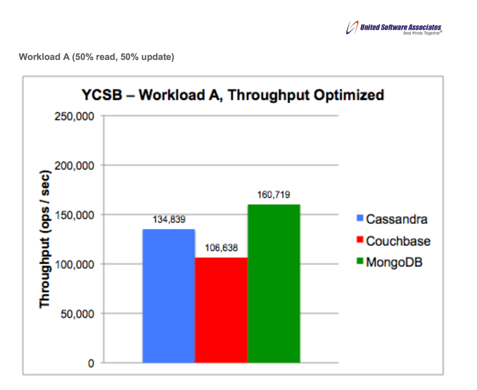
The report presented by Munga’s friends don’t talk (much) about the use cases in which we are interested; about 95% write and 5% read operations. It would have been nice to have those results as well.
In current use case with data generated by sensors, typical Internet of things scenario, the rate of data generation and storage requirement demands higher write efficiency. This has been provided by Apache Cass at the cost of read flexibility (limited field level querying) and read performance.
Closing Remarks
With the current hype/breakthrough around Intelligent systems (read AI, Machine Learning, Deep Learning, Self-Driving Cars etc.) It would be fascinating to look at system architecture as an evolving organism, a human body per se. Each component is an agent, the system together is a multi-agent system. Each agent believing in greater good than individual — in the lines of Nash equilibrium in the Game Theory. In our hypothetical story, imagine Munga coming up with new features in 2019 that add value to the current production system deployed with Apache Cass. Then Apache Cass writing an email to the Architect informing about its better replacement. Wouldn’t that be an awesome (r)evolution?
Isn’t evolution the key reason for Intelligence?
In the specific use case a physical device is wore by the user. This device has high tech sensors whose primary role is to capture health related vitals of/from the user. Above article is in the lines of architecture design for the system.